
超全面详细的身份证号码编码原理
摘要 身份证号码是国家为每个公民从出生之日起编定的唯一的、终身不变的的代码。身份证上的号码你知道都代表什么意思吗?为什么有些人身份证号码最后一位是X?今天博主就向大家仔细的介绍一下身份号码的组成、含义以及编码的原理。相信你看完本文以后,一定会对身份号码有一个清晰、透彻的理解。 首先简要介绍一下身份号码的组成及含义。 国标GB 11643规定,全国所有公民的身份号码都是18位的特征码。所谓特征码,就是号...

身份证号码是国家为每个公民从出生之日起编定的唯一的、终身不变的的代码。身份证上的号码你知道都代表什么意思吗?为什么有些人身份证号码最后一位是X?今天博主就向大家仔细的介绍一下身份号码的组成、含义以及编码的原理。相信你看完本文以后,一定会对身份号码有一个清晰、透彻的理解。
首先简要介绍一下身份号码的组成及含义。
国标GB 11643规定,全国所有公民的身份号码都是18位的特征码。所谓特征码,就是号码本身反映了公民的一些基本特征,比如籍贯、年龄、性别等。
身份号码前6位是地址码,表示公民出生时户口所在地的地址,此后不随户籍变化而改变。
紧接着的8位是出生日期码,表示公民出生的具体日期。
接下来的3位是顺序码,区县公安机关按顺序给辖区内同年同月同日出生的公民进行编码。顺序码除了起到区分同辖区内同年同月同日出生的公民,还包含了公民的性别特征,公安机关在编制顺序码时,对男性公民编制为奇数,女性为偶数。
最后一位是校验码,引入校验码的目的,是为了避免输入错误。因为身份号码本体码长达17位,这么长的数字串,在录入电脑系统时,难免输错。引入校验码以后,电脑系统就能根据预定的算法检测出录入是否有误,从而确保录入的正确性。
校验码是根据前面17位本体码数字的值,按照统一的算法计算出来的。计算出的校验结果可能为0~9,还可能为10。如果是10,就用X替代。之所以要用单字符X替代两位数的10,是为了身份号码位数的统一。统一的位数有助于系统的管理与维护。而之所以用X而不是ABC或其他字符来替代,是因为在罗马字符中X恰好就是表示序号10的意思。

下面分别详细介绍各组成部分的编码原理。
一、地址码
地址码表示编码对象(即公民)常住户口所在县(市、旗、区)的行政区划代码,按国标GB/T 2260的规定执行。
国标GB/T 2260规定了我国县级及县级以上行政区划的数字代码和字母代码。其中的数字代码采用三层六位的层次结构,按层次分别表示我国省(自治区、直辖市、特别行政区)、市(地区、自治州、盟)、县(自治县、县级市、旗、自治旗、市辖区、林区、特区)。
行政区划数字代码码位结构从左到右的含义是:
第一层即前两位代码表示省、自治区、直辖市、特别行政区。
按照国务院目前的划分,我国有34个省(自治区、直辖市、特别行政区),数量超过了10个所以1位数字不够用,需要采用2位数字来进行编码。
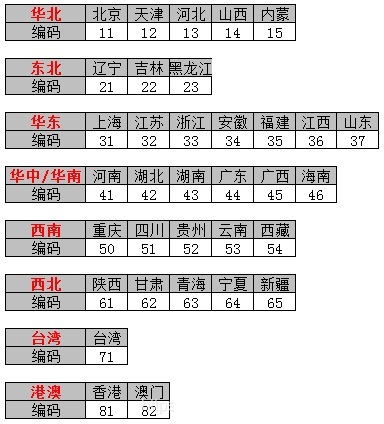
虽然国标GB/T 2260没有明确指明,但通过其具体编码可以看出:为了适应以后省级行政区划的变更,国标GB/T 2260对这34个省并不是按照顺序进行编码的,而是按照各省所在区域,又划分为华北、东北、华东、华中华南、西南、西北、台湾、香港澳门等8个大的区域,每个区域包含3~7个省级区划。用第一位表示区域码,第二位表示该区域内的省的编码。
引入区域的概念后,既保持了各省代码的相对连续,又方便了以后对省级行政区划变更的扩展。
比如重庆市以前是隶属于四川省的一个省辖市,升级为直辖市后,新的代码就从西南区域中分配(新分配到的区划代码是50)。假如以后深圳市也有机会升级为直辖市的话,就可以从华南区域分配省级区划代码(比如40或47~49)。目前各区域都预留有4~7个代码作为备用。
具体的区域编码如下图所示:(注:区域编码是博主总结的,国标里面并没有明确规定)

各省(自治区、直辖市、特别行政区)的编码如下图所示:(下面编码是国标规定的,不是博主胡乱编造的)
第二层即中间两位代码表示市、地区、自治州、盟、直辖市所辖市辖区/县汇总码、省(自治区)直辖县级行政区划汇总码,其中:
—01~20/51~70表示市,01、02还用与表示直辖市所辖市辖区/县汇总码;
—21~50表示地区、自治州、盟;
—90表示省(自治区)直辖县级行政区划汇总码。
上面这段话可能比较晦涩,参照下图来看就很好理解了。

第三层即后两位表示县、自治县、县级市、旗、自治旗、市辖区、林区、特区,其中:
—01~20表示市辖区、地区(自治州、盟)辖县级市、市辖特区以及省(自治区)直辖县级行政区划中的县级市,01通常表示市辖区汇总码;
—21~80表示县、自治县、旗、自治旗、林区、地区辖特区;
—81~99表示省(自治区)辖县级市。
这段话也比较晦涩,也请参照下图来理解。

二、出生日期码
出生日期码表示编码对象(公民)出生的年、月、日,按国标GB/T 7408的规定执行,年、月、日代码之间不用分隔符。
表示日期的方式有很多种,比如可以采用年月日的方式,也可以采用年周的方式。年月日还可以有不同的编码:20170825、2017825、8252017、2582017等都可以表示2017年8月25日。身份号码里的出生日期码则只能采用20170825这一种方式。这也是最符合我们中国人习惯的一种方式。
三、顺序码
顺序码表示在同一地址码所标识的区域范围内,对同年、同月、同日出生的人编定的顺序号,顺序码的奇数分配给男性,偶数分配给女性。
对于顺序码,国标GB 11643只规定了其位数为三位数字,并要求奇数分配给男性,偶数分配给女性,除此之外,没有对其做进一步细化。这就给了区县级公安机关根据本区县实际情况灵活编制的权利。
从实际身份证号码来看,区县级公安局在编制顺序码时,应该是将乡镇/街道区划代码融入进了顺序码中。
国标GB/T 10114规定,县级以下行政区划指镇、乡、民族乡及街道;县级以下行政区划代码由三位数字构成,具体划分为:001~099表示街道;100~199表示镇、民族镇;200~399表示乡、民族乡、苏木(内蒙的基层行政单位)。
从上面规定可以看出,国标GB/T 10114只是对县级以下行政区划代码作了一个框架性的规定,具体的编码交由各省、自治区、直辖市标准化管理机构负责编制并作为地方标准。因此,各省的县级以下行政区划代码的编码规则不一定完全相同。
细心的读者可能会有担心,3位顺序码最多容纳1000人,如果某一区县在某一天同时有500个以上的男性或女性出生,那么第501个及其后面的人显然就分配不到合法的身份号码。
其实这个问题无需我们担心,相关部门在制定这个标准时,已经根据我国的人口现状,各区县在以往历年的出生人口统计中确知,所有区县的一天出生人口远远达不到500个之多。
四、校验码
校验码采用ISO 7064:1983,MOD 11-2校验算法对前面的地址码、出生日期码和顺序码进行校验。具体校验公式如下图所示:
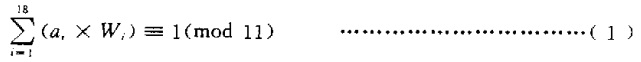
公式中:i表示号码字符从右至左包括校验码字符在内的位置序号,ai表示第i位置上的号码字符值;wi表示第i位置上的加权因子,其数值依据公式wi=(2^(i-1))(mod 11)计算得出。根据这个公式,小编推导出了另一个公式:w1=1,wi=(2*w(i-1))(mod 11)。(其中w(i-1)是一个整体,表示上一个w,头条不支持下标输入,大家将就着看)。这两个公式是等价的,但是推导公式与更便于计算。下图是小编为大家计算出的wi在各位置上的值。

上面的校验公式(1)表示了什么意思呢,估计很多读者看到它直犯晕。这里解释一下,其实意思不复杂,就是:加入校验码后,身份号码所有位置(包括校验码)上的数字乘以该位置上的加权因子再求和,再对11求模,其结果要等于1。
那我们要怎么计算校验位呢?
只需将上面公式稍作变换,具体是将a1×w1从求和表达式中提取出来,因为w1=(2^(1-1))(mod 11)=1,于是我们就得到了下面的公式:

公式中a1就是我们要求的校验码字符值,其取值范围是0~10。当a1=10时,用罗马字符X表示。
根据上面公式(2),只要求出第2~18位的∑ai×wi ,就能换算出校验码的值。具体换算表如下图所示:

肯定还有不少读者要问,上面这个换算表是怎么来的?以最右边的10为例解释一下,与10相加后对11取模等于1的数有:2、13、24、35、46等等无数多个,但是在0~10范围内的就只有2;所以10换算后为2,其他的类推。其实说白了就是,二者相加后,等于11的倍数加1。
下面举例介绍校验码的详细计算方法,假设某男性公民身份号码的本体码为11010820171221591,其校验码字符值的计算方法及步骤为:
第一步,列出该身份号码的本体码,结果如下:(待计算的校验码也一并列出来)

第二步,依据公式wi=(2^(i-1))(mod 11)计算加权因子,结果如下:

第三步,计算各位置上的乘积,结果如下:

第四步,乘积求和:∑ai×wi=7+9+0+5+0+32+4+0+6+21+7+18+20+5+40+36+2=212。
第五步,对11取模:∑ai×wi(mod 11)=212%11=3。
第六步,求出校验码字符值,根据(3+a1)≡1(mod 11),算出a1=9。
因此,该男性公民身份号码的本体码为110108201712215919。
到这里完整的身份证编码原理就全部介绍完了。